Ở bài viết này tôi sẽ giới thiệu một cách tiếp cận để tìm các lỗi trên các ứng dụng closed-source bằng phương pháp fuzzing. VMware Workstation là một ví dụ thú vị để làm, hãy đi qua từng phần tôi trình bày dưới đây để hiểu rõ hơn về target này.
Giới thiệu
Enhanced metafile format (EMF) là một định dạng tập tin có thể chứa nhiều dạng dữ liệu được lưu dưới dạng bản ghi (record), thông thường bao gồm định dạng tập tin đồ họa như bitmap, ảnh, text,…
Enhanced metafile spool format (EMFSPOOL) là một định dạng tệp được sử dụng để lưu trữ, định nghĩa của các lệnh in (print jobs), xuất ra hình ảnh đồ họa. Các tệp EMFSPOOL chứa một chuỗi các bản ghi (record) để xử lý và phân tích cú pháp, chạy lệnh in (print jobs) trên bất kỳ thiết bị đầu ra nào.
Để hiểu rõ về định dạng này, có thể tham khảo thêm document của Microsoft [1][2] cũng như whitepaper của j00ru [3]. EMF được sử dụng rất nhiều trong print spooling, với việc sử dụng trong print spooling dẫn đến có nhiều attack surface vì nó có nhiều bản ghi với mỗi bản ghi lại lưu trữ các định dạng file khác nhau như là ảnh, phông chữ,…
Trong quá trình tìm hiểu tôi nhận thấy EMFSPOOL được sử dụng trong VMware Workstation.
Virtual Printer
Đây là một tính năng cho phép guest machine in tài liệu bằng các máy in có sẵn trên host machine (về cơ bản là chia sẻ máy in). Với cách gửi dữ liệu từ guest machine ra host machine, có thể xem đây là một hướng tấn công VM escape.
Trong quá khứ, vào năm 2015 một loạt lỗi được Kostya Kortchinsky report trong đó có lỗi stack overflow và anh ấy đã viết được exploit khai thác thành công [4]. Đến năm 2016, j00ru sử dụng fuzzing tìm ra thêm một loạt các lỗi liên quan đến các định dạng ảnh JPEG2000, EMF, phông chữ,… [5][6]
Virtual printer không được bật mặc định trên VMware Workstation. Để bật nó ta cần cài đặt như sau:
Về kiến trúc cũng như cách hoạt động, hướng tấn công của Virtual Printer, ta quan sát hình dưới:
Process chúng ta sẽ chú ý đến là vprintproxy.exe được khởi chạy trên host machine. Dữ liệu được gửi từ guest machine đến process vprintproxy.exe ở host machine thông qua cổng COM1. Dữ liệu được gửi đi từ guest machine không yêu cầu bất cứ quyền gì, tức là bất kì user nào cũng có thể tiến hành gửi dữ liệu đi. Dữ liệu gửi ra host machine được định nghĩa theo định dạng EMFSPOOL. Với định dạng này nó cho phép ta có thể đính kèm thêm các định dạng file khác qua các bản ghi như ảnh, EMF, phông chữ,…
TPView
Bằng việc tận dụng lại các POC do j00ru public từ trước [5] [6], tôi đã chỉnh sửa một chút cho phù hợp với phiên bản hiện tại, sử dụng nó và debug luồng xử lý data của Virtual Printer, tôi nhận thấy:
- Quá trình xử lý data đều nằm trong TPView.dll.
- Dữ liệu truyền từ guest machine đến host machine chỉ được xử lý tại TPView.dll, trên đường truyền dữ liệu không bị đối tượng nào tác động để thay đổi.
Khi phân tích file TPView.dll, tôi nhận thấy Virtual Printer xử lý một số bản ghi đính kèm các định dạng file như: JPEG2000, OTF, TTF,…
JPEG2000
Đối với bản ghi jpeg2000, đây là một bản ghi được TPView.dll custom thêm vào EMFSPOOL. j00ru phát hiện thư viện xử lý ảnh jpeg2000 của Irfanview và TPView.dll có chung code base đối với phần xử lý ảnh. Anh ấy đã port thư viện của Irfanview sang Linux và tiến hành fuzz trên đó. Đó là một cách làm thông minh và cải thiện được khá nhiều hiệu năng, tuy nhiên tôi không có kinh nghiệm port DLL sang Linux (mặc dù có khá nhiều ví dụ như LoadLibrary của Taviso [7] hay harness fuzz TTF của j00ru [8]), do vậy tôi quyết định reverse và xây dựng harness xoay quanh TPView.dll.
Trong quá trình reverse và debug tôi nhận thấy hàm sub_100584CE sẽ tiến hành xử lý bản ghi JPEG2000 gửi từ guest machine ra. Trong hàm sub_100584CE, chương trình tiến hành decompress dữ liệu và kiểm tra các trường trong data đó (do dữ liệu truyền từ guest machine ra đã được compress bằng zlib).
Kết quả của hàm decompress_data như sau:
Tôi kiểm tra hàm check_record (hàm này sẽ kiểm tra các trường có trong dữ liệu sau khi decompress) và tạo lại được struct record_jp2k và struct header chứa các trường như sau:
Khi decompress data và kiểm tra thỏa mãn các trường xong, chương trình tiếp tục tính toán và lấy các giá trị trong struct record_jp2k và header để xử lý hình ảnh jpeg2000.
Ta quan sát thấy từ dòng 84 đến dòng 110 chương trình tiến hành tạo một record_jp2k v20 để lưu trữ dữ liệu jpeg2000 sau khi xử lý. Và hàm process_jp2k chính là hàm parsing/process hình ảnh jpeg2000.
Ta thấy hàm process_jp2k nhận vào các tham số sau:
- header->data_jp2k: dữ liệu file ảnh jpeg2000
- header: struct header
- record->len_jp2k: kích thước file jpeg2000
- v20->hdr: struct lưu dữ liệu sau khi xử lý của ảnh jpeg2000
- val_0x328: kích thước của record output với giá trị 0x328
Từ những tham số truyền vào ở trên thì hàm process_jp2k hoàn toàn có thể sử dụng để làm entry point của harness. Vì dữ liệu đưa vào rất sát với dữ liệu của hình ảnh jpeg2000 và nó không phụ thuộc nhiều vào các giá trị khác trong EMFSPOOL.
Dưới đây là harness mà tôi xây dựng để fuzz EMFSPOOL với record chứa file ảnh jpeg2000.
Phông chữ
Đối với bản ghi phông chữ, TPView.dll hỗ trợ xử lý đầy đủ 5 bản ghi mà EMFSPOOL có sẵn:
- EMRI_ENGINE_FONT: Định dạng TTF
- EMRI_TYPE1_FONT: Định dạng OTF
- EMRI_DESIGNVECTOR: Chứa font’s design vector
- EMRI_SUBSET_FONT: Chứa một phần phông chữ ở định dạng TTF
- EMRI_DELTA_FONT: Chứa các glyph được merged với dữ liệu từ bản ghi EMRI_SUBSET_FONT trước đó.
Với mỗi bản ghi, TPView.dll sẽ có những phần xử lý khác nhau. Tuy nhiên ta có thể tham khảo tại document của Microsoft [2] về các bản ghi này.
Sau khi debug luồng xử lý bản ghi phông chữ của TPView, tôi thấy hàm sub_10013B06 sẽ là hàm tiếp nhận dữ liệu phông chữ gửi từ guest machine ra và xử lý.

Hàm này nhận vào 5 tham số tương ứng như sau:
flag là tham số đầu tiên của hàm, với mỗi giá trị flag sẽ biểu thị cho một bản ghi cụ thể:

Các tham số còn lại tôi kiểm tra qua WinDbg, đặt breakpoint tại hàm sub_10013B06. Tham số thứ 2 ở đây nó chứa một vùng nhớ kích thước 12 byte và được khởi tạo bằng NULL. Ta có thể kiểm tra giá trị đó qua hình dưới đây, ecx lưu trữ tham số thứ 2:
3 tham số còn lại như hình dưới ta có thể thấy vùng nhớ có địa chỉ 0x4453DD8 (argv3) là vùng nhớ chứa bản ghi phông chữ, tham số thứ 4 (argv4) là kích thước của vùng nhớ này. Tham số thứ 5 (argv5) có kích thước 1 byte và tôi kiểm tra qua một số lần chạy thì giá trị này luôn luôn là 1.
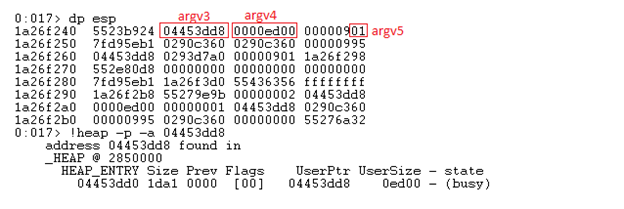
Đối với tham số thứ 3 (argv3) là dữ liệu bản ghi của phông chữ, với mỗi bản ghi chúng ta có một cấu trúc khác nhau nhưng ta hoàn toàn có thể tham khảo document của Microsoft [9] để hiểu thêm về cấu trúc đó. Tôi lấy ví dụ về bản ghi EMRI_ENGINE_FONT, hình dưới đây mô tả về các trường trong cấu trúc của một bản ghi EMRI_ENGINE_FONT. Tuy nhiên trong trường hợp này bản ghi lưu trong tham số thứ 3 sẽ bắt đầu từ trường Type1ID trở đi.
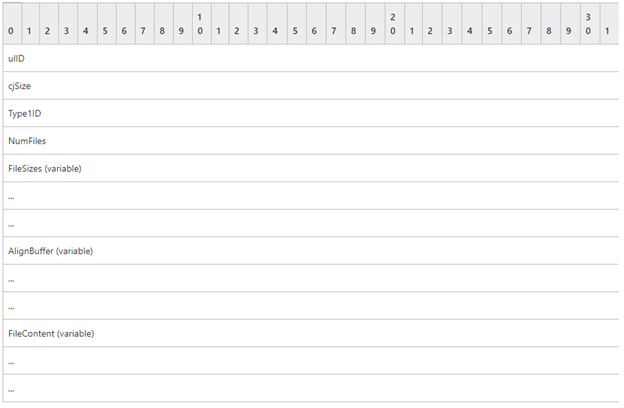
Ý nghĩa của từng trường trong hình ảnh trên như sau:
- Type1ID (4 bytes): Một giá trị số nguyên (không âm) 32-bit, giá trị này phải là 0x00000000 để biểu thị cho định dạng TTF.
- NumFiles (4 bytes): Một giá trị số nguyên (không âm) 32-bit biểu thị số lượng file TTF được đính kèm trong bản ghi.
- FileSizes (variable): một mảng chứa kích thước của các file TTF đính kèm trong bản ghi.
- AlignBuffer (variable): padding buffer.
- FileContent (variable): chứa data của file TTF.
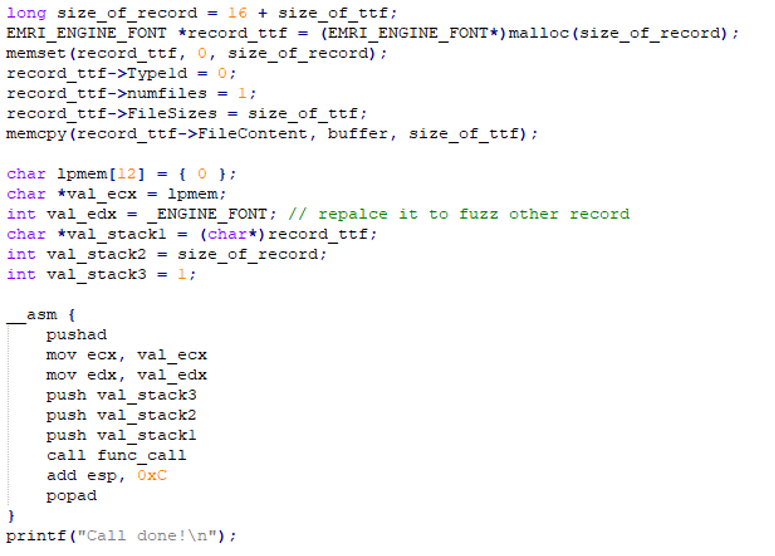
Ở trong trường hợp này của tôi, tôi sẽ chỉ sử dụng một file TTF cho mỗi bản ghi do đó struct EMRI_ENGINE_FONT tôi khởi tạo như sau:

Kiểm tra tham số này trên WinDbg ta có tương ứng các trường như sau:

Đến đây ta hoàn toàn có thể xây dựng harness để fuzz bản ghi phông chữ này bằng việc gọi hàm sub_10013B06. Dựa vào những thông tin tôi có ở trên thì dưới đây là mẫu harness fuzz bản ghi EMRI_ENGINE_FONT, các bản ghi khác đều tương tự chỉ thay đổi tham số flag.
EMF
Ngoài các bản ghi về JPEG2000 và phông chữ thì TPView.dll còn handle bản ghi EMRI_METAFILE, là định dạng file EMF. Sau khi nhận data từ guest machine, TPView.dll tiến hành xử lý phần data chứa nội dung file EMF. Cơ bản nó ghi data đó ra thư mục %temp% dưới dạng file và gọi các API của Windows để xử lý file này như: GetEnhMetaFileW, EnumEnhMetaFile, PlayEnhMetaFileRecord, GetEnhMetaFileHeader, GetEnhMetaFilePaletteEntries, …
Tuy nhiên ta sẽ chú ý đến API EnumEnhMetaFile:
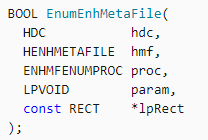
Đây là hàm thường được sử dụng để xử lý các bản ghi chứa trong file EMF qua 1 callback là tham số thứ 3 của API này. API này được sử dụng ở trong hàm sub_10042BB6 của thư viện TPView.dll. Sau khi xem xét callback này, tôi quyết định chọn callback này sẽ là hàm mà tôi muốn fuzz vì hàm này chính là hàm sẽ parsing/process các bản ghi trong file EMF.

Như hình trên ta có thể thấy callback là hàm proc, tuy nhiên cái khó ở đây là xác định tham số thứ 4 tức là param cho hàm callback. Do param là biến cục bộ dẫn đến việc trace ngược lại để recover lại được các trường trong param cũng mất nhiều thời gian. Gặp những trường hợp như thế này tôi thường phải reverse static một chút và đoán dần các trường rồi debug để kiểm tra nó.
Đầu tiên ta hãy đoán kích thước của nó.

Quan sát các biến cục bộ được định nghĩa trong hàm sub_10042BB6, ta để ý thấy biến param bắt đầu từ ebp+0h theo sau đó là một loạt các biến khác. API EnumEnhMetaFile được sử dụng trong hàm có tham số thứ 5 là một struct RECT, tương ứng trong hàm sub_10042BB6 là biến xDest nằm ở vị trí ebp+98h. Qua đó, tôi nhận ra rằng kích thước của biến param lớn nhất chỉ có thể là 0x98 vì nếu vượt quá kích thước này nó sẽ đè lên biến xDest (tham số thứ 5 của API EnumEnhMetaFile).
Tôi tạo một struct param_s với kích thước 0x98 bao gồm các trường như trên. Tiếp tục recover các trường còn lại trong struct.

Dòng 75 và 101 trong hàm sub_10042BB6 tiến hành khởi tạo biến v23 và v26 bằng API GetDeviceCaps. Dẫn đến ta có 2 giá trị v23 và v26 trong struct là một giá trị int devcap.

Tiếp đến ta đặc biệt chú ý 4 trường v13, v21, v24, v25 trong struct, tôi sẽ đi lần lượt qua 4 trường này:
1. Trường v13
Trường này được truyền vào hàm sub_100A68D2:
Đây là hàm khởi tạo struct CStringList, nhìn vào hàm sub_100A68D2 tôi tạo lại struct CStringList như sau:
Struct CStringList này có kích thước 0x1C nên các trường từ v13 -> v19 trong struct param_s là vùng nhớ của struct CStringList. Lúc này struct param_s của tôi được cập nhật như sau:

Ta có thể khởi tạo CStringList bằng code như sau:
2. Trường v21
Không giống như trường v13, trường v21 được gán từ một vùng nhớ khác thông qua hàm sub_1000F8EA. Hàm sub_1000F8EA tiến hành gán một vùng nhớ có kích thước 8 bytes:
Do đó hàm này sẽ khởi tạo 2 trường liên tiếp trong struct param là v21 và v22. Vì được gán giá trị từ một vùng nhớ khác nên khi làm tĩnh rất khó để thấy. Tôi debug, đặt breakpoint trước khi gọi API EnumEnhMetaFile.
Ta thấy struct param_s nằm ở địa chỉ 0x4AAF57C, các trường v21 và v22 lần lượt có kích thước là 0x1c và 0x10 nằm ở các địa chỉ như trong hình. Kiểm tra các địa chỉ tpview!TPRenderW+221858 và tpview!TPRenderW+2228cc tôi biết được hàm sub_1001B7FD sẽ khởi tạo vùng nhớ gán vào v21 và hàm sub_1004559D sẽ khởi tạo vùng nhớ vào trường v22. Tôi reverse 2 hàm sub_1001B7FD và sub_1004559D để xác định các trường của các vùng nhớ mà nó tạo. Qua đó struct param_s của tôi update như sau: (các tên của struct tôi đặt theo ý thích và thói quen)

Tôi khởi tạo các struct ở trên như sau:
3. Trường v24, v25
Tương tự như v21, tôi cũng debug và kiểm tra các hàm khởi tạo 2 trường v24 và v25, kết quả tôi có được như sau:
Và đây là code tôi dùng để khởi tạo hai trường v24 và v25:
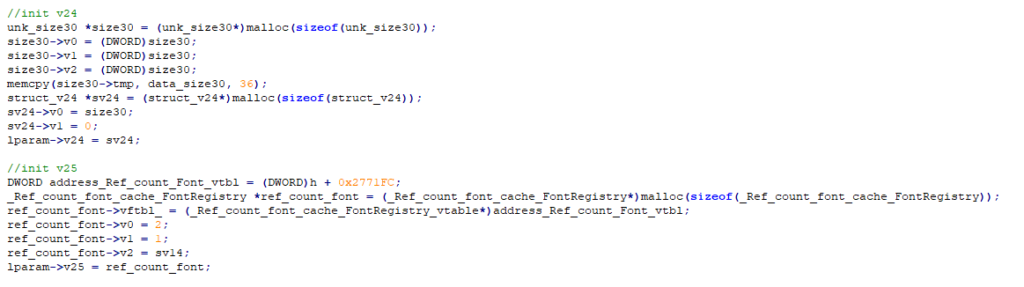
Đến đây tôi đã có thể tạo được param cho API EnumEnhMetaFile, đơn giản là chỉ cần gọi API EnumEnhMetaFile và truyền tham số vào để hoàn thiện harness:

Đến đây tôi đã trình bày cách tạo ra các harness để fuzz thư viện TPView.dll. Với những harness tôi giới thiệu ở trên, đều có thể áp dụng Winafl, pe-afl hay Tiny-afl (tool tôi xây dựng dựa trên TinyInst) để fuzz. Corpus để fuzz đối với định dạng jpeg2000, phông chữ có rất nhiều trên internet (có thể tham khảo tool tạo phông chữ của j00ru [10] [11]). Đối với file EMF tôi tạo một chương trình generate các file EMF chứa một số bản ghi phổ biến như bitmap, control, comment, clipping,…
Kết quả
Bản ghi JPEG2000: 1 bug memory corruption.
Bản ghi Phông chữ: 2 bug integer overflow (CVE-2020-3989 và CVE-2020-3990)
Ngoài ra trong quá trình reverse tôi phát hiện 1 số issues không phải security bug như:
- Sai luồng xử lý của bản ghi EMRI_TYPE1_FONT do kiểm tra các trường không chính xác
- Chạm int 3 do xử lý ngoại lệ khi parsing file EMF không tốt dẫn đến DOS.
Kết luận
Qua bài viết này tôi đã giới thiệu cho mọi người một cách tiếp cận xây dựng harness để fuzz ứng dụng closed-source. Đây là một ví dụ tốt để những người mới bắt đầu học fuzz có thể tham khảo. Những thứ tôi nêu ra chỉ là 1 phần xử lý của TPView.dll mà tôi biết được. Code base của TPView.dll rất lớn, tôi vẫn chưa hiểu hết được, có thể còn một số attack surface mà tôi không biết (có thể vẫn còn nhiều bug, mọi người có thể thử). Hi vọng qua bài viết này có thể giúp mọi người tiếp cận fuzzing dễ dàng hơn và sớm có bug.
Tài liệu tham khảo
[1] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emf/91c257d7-c39d-4a36-9b1f-63e3f73d30ca
[2] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emfspool/3d8cd6cc-5287-42e8-925f-4a53afd04534
[3] https://j00ru.vexillium.org/talks/pacsec-windows-metafiles-an-analysis-of-the-emf-attack-surface-and-recent-vulnerabilities/
[4] https://bugs.chromium.org/p/project-zero/issues/detail?id=287&q=VMware&can=1
[5] https://bugs.chromium.org/p/project-zero/issues/detail?id=850&q=VMware&can=1
[6] https://bugs.chromium.org/p/project-zero/issues/detail?id=848&q=VMware&can=1
[7] https://github.com/taviso/loadlibrary
[8] https://github.com/googleprojectzero/BrokenType/tree/master/fontsub-dll-on-linux
[9] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emfspool/ed79f9d8-31fb-46cb-950e-ea7682f50c70
[10] https://github.com/googleprojectzero/BrokenType/tree/master/truetype-generator
[11] https://github.com/googleprojectzero/BrokenType/tree/master/ttf-otf-mutator