In this article, I will introduce an approach to find bugs on closed source applications using the fuzzing method. VMware Workstation is an interesting example to do, please go through each part I present below to better understand this target.
Introduction
Enhanced metafile format (EMF) is a file format that is used to store portable representations of graphical images. EMF metafiles contain sequential records that are parsed and processed to render the stored image on any output device.
Enhanced metafile spool format (EMFSPOOL) is a file format used to store portable definitions of print jobs that output graphical images. EMFSPOOL metafiles contain a sequence of records that are parsed and processed to run the print job on any output device.
To understand this format, can refer to Microsoft document [1] [2] as well as the whitepaper of j00ru [3].
EMF is used a lot in print spooling, with its use in print spooling leading to a lot of attack surfaces because it combines many file formats stored in records such as images, fonts,…
During my research, I noticed that EMFSPOOL was used in VMware Workstation.
Virtual Printer
This is a feature that allows guest machines to print documents using available printers on the host machine (basically printer sharing). By sending data from the guest machine to the host machine, this can be seen as a way to attack the VM escape.
In the past, in 2015 a series of bugs were reported by Kostya Kortchinsky including the stack overflow bug and he built the exploit successfully [4]. By 2016, j00ru continued to use fuzzing to find out a series of bugs related to image formats JPEG2000, EMF, fonts,… [5] [6]
Virtual Printer is not enabled by default on VMware Workstation. To turn it on we need the following settings:
About the architecture as well as how it works, the attack surface of the Virtual Printer, we can see the picture below:
The process we are interested in is vprintproxy.exe which is launched on the host machine. Data is sent from the guest machine to the vprintproxy.exe process on the host machine via port COM1. Data sent from the guest machine does not require any permissions, meaning any user can send data. Data sent to the host machine is defined in the format EMFSPOOL. With this format it allows you to attach other file formats to records such as images, EMFs, fonts,…
TPView
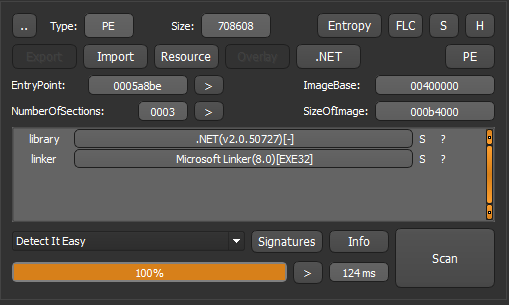
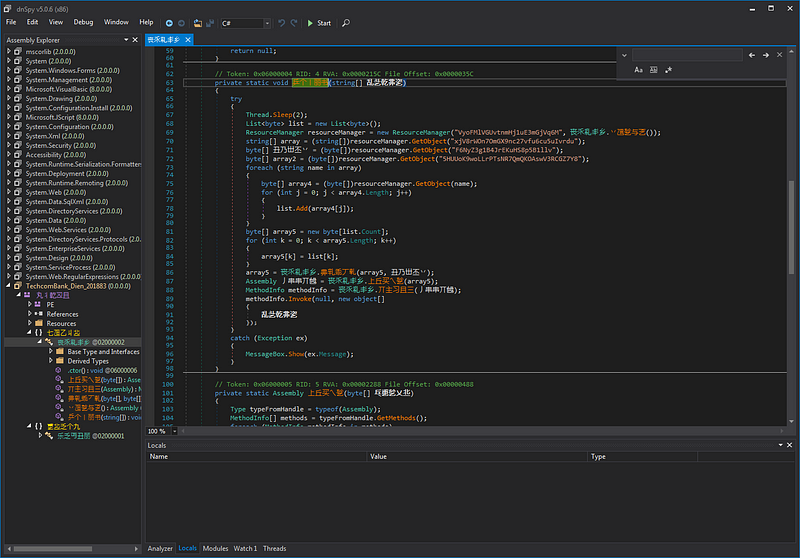
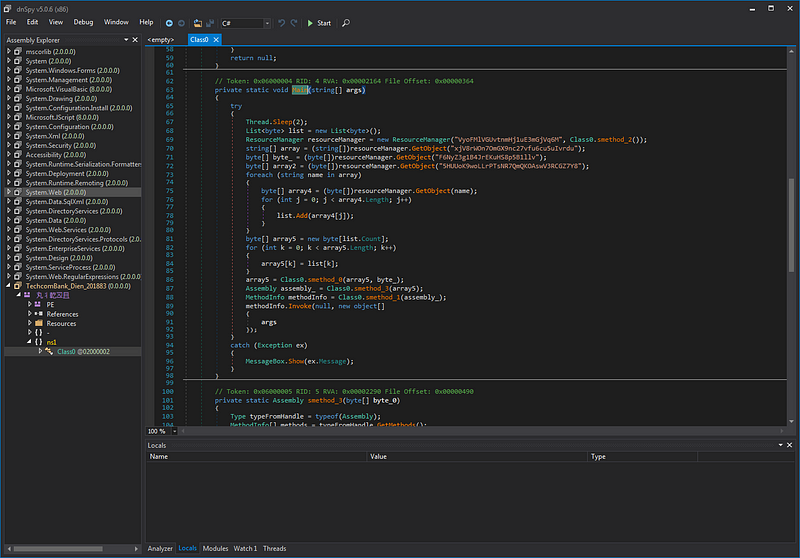
By taking advantage of the POCs made by j00ru public from before [5] [6], I made a little tweaking to fit the current version, using it and debugging the Virtual Printer’s data processing flow, I found that:
- The data processing is in TPView.dll
- Data transmitted from the guest machine to the host machine is only processed at TPView.dll, on the data transmission line, it is not affected by any object to change.
When analyzing TPView.dll, I saw the virtual printer handling some records with file formats such as JPEG2000, OTF, TTF,…
JPEG2000
For jpeg2000 record, this is a record added by TPView.dll to EMFSPOOL. j00ru discovered that Irfanview’s jpeg2000 image processing library has the same code base for image processing in TPView.dll. He ported Irfanview’s library to Linux and did fuzz on it. It’s a smart way to do it and greatly improve the performance. However, I have no experience port DLL to Linux (although there are quite a few examples such as LoadLibrary from Taviso [7] or harness fuzz TTF of j00ru [8]), so I decided to reverse and build harness around TPView.dll.
During reverse and debug I see function sub_100584CE will process the JPEG2000 record sent from the guest machine. In the sub_100584CE function, the program decompresses the data and checks the fields in that data (because the data transferred from the guest machine has been compressed by zlib).
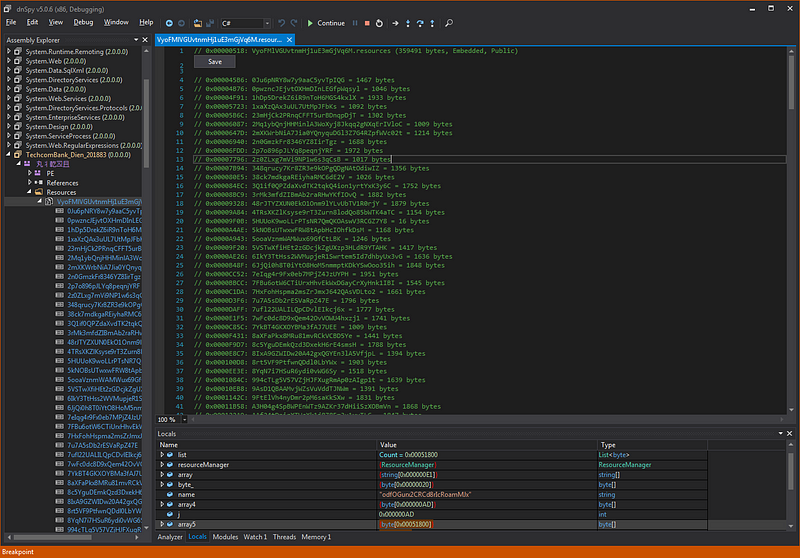
The results of the decompressdata function are as follows:
I check the function check_record (this will check the fields in the data after decompress) and recreate the struct record_jp2k and the struct header contains the following fields:
When the decompress data and check the fields are finished, the program continues to compute and get the values in struct record_jp2k and header to process the jpeg2000 image.
We observe from line 84 to line 110 the program creates a record_jp2k v20 to store jpeg2000 data after processing. And process_jp2k function is parsing/process image jpeg2000.
We see the function process_jp2k takes the following parameters:
- header->data_jp2k: jpeg2000 image file data
- header: struct header
- record->len_jp2k: file size jpeg2000
- v20->hdr: struct saves data after processing of jpeg2000 images
- val_0x328: The size of the output record with the value 0x328
I have found that the function process_jp2k can be completely used as the entry point of a harness. Since the input data is very similar to the data of the jpeg2000 image and it does not depend much on other values in EMFSPOOL.
Below is a harness that I built to fuzz EMFSPOOL with a record of jpeg2000 image file
Font
For font records, TPView.dll supports the full processing of 5 records that EMFSPOOL is available:
- EMRI_ENGINE_FONT: Defines a font in TrueType format.
- EMRI_TYPE1_FONT: Defines a font in PostScript Type 1 font format.
- EMRI_DESIGNVECTOR: Contains a font’s design vector, which characterizes a font’s appearance in 16 properties.
- EMRI_SUBSET_FONT: Contains a partial font in TrueType format, with enough glyph outlines for pages up to the current page.
- EMRI_DELTA_FONT: Contains new glyphs to be merged with data from a preceding EMRI_SUBSET_FONT record.
For each record, TPView.dll will have different handlers. However, we can refer to the Microsoft document [2] about these records.
After debugging the TPView’s font record processing flow, I found the sub_10013B06 function would be the function that takes the font data sent from the guest machine and processes it.

This function takes the following 5 parameters:
flag is the first parameter of the function, with each flag value representing a particular record:

The remaining parameters I check via WinDbg, set a breakpoint at function sub_10013B06. The second argument I see is that this parameter contains a 12-byte memory area and is initialized with NULL. We can check that value in the figure below, the ecx register stores the second parameter:
The remaining 3 parameters as shown below, we can see that the memory address 0x4453DD8 (argv3) is the memory that contains the font record, the fourth parameter (argv4) is the size of this memory. The 5th parameter (argv5) is 1 byte in size and I check it through a number of runs, this value is always 1.
For the third parameter (argv3) is the font’s record data, for each record we have a different structure, but we can completely refer to Microsoft’s document [9] to understand more about that structure. I take an example of an EMRI_ENGINE_FONT record, the following figure describes the fields in the structure of an EMRI_ENGINE_FONT record. However in this case the record stored in parameter 3 will start from the Type1ID field onwards.
The meanings of each field in the image above are as follows:
- Type1ID (4 bytes): A 32-bit unsigned integer. The value MUST be 0x00000000, to indicate a TrueType.
- NumFiles (4 bytes): A 32-bit unsigned integer that specifies the number of files attached to this record.
- FileSizes (variable): Variable number of 32-bit unsigned integers that define the sizes of the files attached to this record.
- AlignBuffer (variable): Up to 7 bytes, to make the data that follows 64-bit aligned.
- FileContent (variable): Variable-size, 32-bit aligned data that represents the definitions of glyphs in the font. The content is in TrueType format.
In my case, I will only use 1 TTF file per record so the EMRI_ENGINE_FONT struct I initialize as follows:

Check this parameter on WinDbg we have corresponding fields as follows:

At this point, we can completely build a harness to fuzz this font record by calling the sub_10013B06 function. Based on the information I have above, the following is a sample harness fuzz EMRI_ENGINE_FONT record, other records are similar, just change the flag parameter.
EMF
In addition to the JPEG2000 records and fonts, TPView.dll also handles the EMRI_METAFILE record, which is the EMF file format. After receiving data from the guest machine, TPView.dll processes the data containing the contents of the EMF file. It basically writes that data to the %temp% directory as a file and calls the Windows APIs to handle this file as: GetEnhMetaFileW, EnumEnhMetaFile, PlayEnhMetaFileRecord, GetEnhMetaFileHeader, GetEnhMetaFilePaletteEntries,…
However, we will be interested in the EnumEnhMetaFile API:
This is a commonly used API to process the records contained in the EMF file through a callback that is the third parameter of this API. This API is used in the sub_10042BB6 function of the TPView.dll library. After reviewing this callback, I decided to choose this callback as the function I want to fuzz because this function is the function that will parsing/process the records in the EMF file.

As in the picture above, we can see that the callback is the proc function, but I had difficulty finding the 4th parameter, i.e. the param for the callback function. Since the param is a local variable, it takes a long time to trace back to recover the fields in the param. In cases like this, I usually have to reverse static a bit and guess the fields and debug to check it.
Let’s first guess its size.

Looking at the local variables defined in function sub_10042BB6, we notice that the param variable starts at ebp+0h followed by a series of variables. The EnumEnhMetaFile API used in the function has the 5th parameter being a struct RECT, the corresponding in the function sub_10042BB6 is the variable xDest located at ebp+98h. Thereby, I realized that the size of the largest param variable could only be 0x98 because if it exceeds this size it will override the xDest variable (5th parameter of the EnumEnhMetaFile API).
I create a struct param_s with size 0x98 including the fields as above. Continue to recover the remaining fields in the struct.

Lines 75 and 101 in function sub_10042BB6 proceed to initialize the variables v23 and v26 using the GetDeviceCaps API. This leads to 2 values v23 and v26 in the struct, which is an int devcap value.

Next, we pay special attention to 4 fields v13, v21, v24, v25 in the struct, I will go through these 4 fields in turn:
1. Field v13
This field is passed to the function sub_100A68D2:
This is the function that initializes the CStringList structure, look at the sub_100A68D2 function, I recreate struct CStringList as follows:
This CStringList struct has size 0x1C, so the field v13 -> v19 in struct param_s are the memory area of struct CStringList. Now my struct param_s is updated as follows:

We can initialize CStringList with the following code:
2. Field v21
Unlike field v13, field v21 is copied from another place through the sub_1000F8EA function. The function sub_1000F8EA copies a memory area of 8 bytes in size:
Therefore, this function will initialize 2 fields in struct param, v21 and v22. Because it is assigned a value from another memory area, it is difficult to see when doing static. I debug, set breakpoints before calling the EnumEnhMetaFile API.
We see struct param_s located at address 0x4AAF57C, fields v21 and v22 have sizes 0x1c and 0x10 respectively at the addresses shown in the figure. Check the tpview!TPRenderW+221858 and tpview!TPRenderW+2228cc addresses I know function sub_1001B7FD will initialize the memory assigned to v21 and function sub_1004559D will initialize the memory into field v22. I reverse the two functions sub_1001B7FD and sub_1004559D to determine the fields of the memory it creates. Through that, my param_s struct is updated as follows: (The struct names I set according to liking and habit)

I initialize the above struct as follows:
3. Fields v24, v25
Similar to v21, I also debug and check the initialization functions v24 and v25, the results I get are as follows:
And here is the code I use to initialize two fields v24 and v25:
At this point, I was able to generate the param (4th parameter) for the EnumEnhMetaFile API. Now, simply call API EnumEnhMetaFile and pass parameters to complete the harness:

Here I have shown how to create harnesses to fuzz the TPView.dll library. With the harnesses I introduced above, it is possible to apply Winafl, pe-afl, or Tiny-afl (a tool I built based on TinyInst [10] [11]) to fuzz. Corpus to fuzz for jpeg2000 format, fonts are plentiful on the internet (refer to j00ru’s font creation tool). For EMF file I create a program to generate EMF files containing some popular records such as bitmap, control, comment, clipping,…
Result
JPEG2000 record: 1 bug memory corruption.
Font Record: 2 integer overflow bugs (CVE-2020-3989 and CVE-2020-3990)
Also in the reverse process, I discovered some issues that are not security bugs like:
- The EMRI_TYPE1_FONT record’s processing flow is incorrect due to the incorrect field checking
- Hits int 3 due to exception handling when bad EMF file parsing leads to DOS.
Conclusion
Through this article, I have introduced to everyone an approach to building harness fuzzing for closed source applications. Here’s a good example for beginners to learn fuzz to try. What I am showing above is just a part of the TPView.dll I know of. The codebase of TPView.dll is huge, I still do not fully understand, there might be some attack surface I don’t know (there may still be many bugs, everyone can try). Hopefully, this article can help people approach fuzzing more easily and soon have bugs.
References
[1] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emf/91c257d7-c39d-4a36-9b1f-63e3f73d30ca
[2] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emfspool/3d8cd6cc-5287-42e8-925f-4a53afd04534
[3] https://j00ru.vexillium.org/talks/pacsec-windows-metafiles-an-analysis-of-the-emf-attack-surface-and-recent-vulnerabilities/
[4] https://bugs.chromium.org/p/project-zero/issues/detail?id=287&q=VMware&can=1
[5] https://bugs.chromium.org/p/project-zero/issues/detail?id=850&q=VMware&can=1
[6] https://bugs.chromium.org/p/project-zero/issues/detail?id=848&q=VMware&can=1
[7] https://github.com/taviso/loadlibrary
[8] https://github.com/googleprojectzero/BrokenType/tree/master/fontsub-dll-on-linux
[9] https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-emfspool/ed79f9d8-31fb-46cb-950e-ea7682f50c70
[10] https://github.com/googleprojectzero/BrokenType/tree/master/truetype-generator
[11] https://github.com/googleprojectzero/BrokenType/tree/master/ttf-otf-mutator



































{kind=link}